Figure 1
The Fifty Foot Look at Analysis and Design Models
John D. McGregor
About the time I am writing this, a military jet, flying very low, hit and cut the wire supporting an aerial gondola. A number of people were killed. Flying low is dangerous but that is just what we are doing in this column and the last. I will be examining techniques for doing evaluations of analysis and design models from the "50 foot level" as opposed to the "50,000 foot" view of most traditional reviews and inspections. Many object-oriented software development methods have integrated these techniques into the standard development cycle, but often they are bypassed because of the time required. Based on the approach presented here, the throughput will not improve but the yield (defects found per hour of effort will improve greatly.
In the last column I presented three criteria for evaluating analysis and design models. I said that each model should be:
I illustrated these criteria and the testing technique by examining a requirements model that was constructed using use cases. In this column I want to examine two additional types of models to illustrate additional dimensions of the technique.
In that same column I also detailed a process for testing a model. The process steps are:
There is still another reason for this second column. I could have talked about "testing UML models" as opposed to "testing analysis and design models" and limited the discussion to one column. However, UML is just the notation used to represent the information. The level and purpose of the information in an analysis model (What is the system supposed to do?) is quite different from that in a design model (How will it fulfill its responsibilities?). In both of the columns on model testing I have attempted to describe the types of faults that will be found at each level of model regardless of whether you are using UML or the OPEN[2] approach or the next greatest notation.
Each level of model is more precise than its parent down to the code which must be the most precise of all. Correspondingly, each testing effort must become more detailed. In the next two sections I will follow the progression that started with a look at requirements models in the first column and continue this month with architectural models and then design models.
Architectural model
The architectural design model plays a key role in structuring the application classes, but perhaps its most important role is in constraining the connections between those components. It is productive to test this model because many decisions about the design of individual classes and clusters of classes will be made based on fitting into this architectural scheme. Also, if the architecture must be changed late in the product life cycle due to errors that were not detected earlier, the changes will often ripple into many parts of the system. To further compound the severity of late changes, a bad architectural design will often force less than optimal design choices. Even if the late changes made to the architecture are improvements, there may not be sufficient time to bring many individual design choices into line with the new architecture.
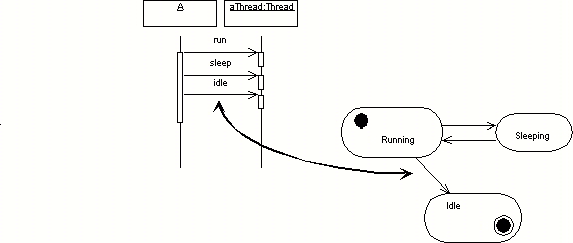
In its basic form, the architectural model is a set of components and the connections between them. I will assume a basic connection/connector approach to architecture such as that discussed in Shaw and Garlan.[11] The UML package diagram and the class diagram are often used to represent this model. Figure 1 includes a package diagram that represents a simple architecture.
|
Figure 1 |
|
|
A fault in an architectural model involves either the components, the connectors or an interaction of the two. The model would be incorrect if there is a connection between two subsystems that do not need to communicate. This probably is not a high-priority fault because the developer may simply not send any message corresponding to the connection when they create the detailed implementation. However, the presence of this association sets a incorrect expectation, represents an unnecessary coupling and may lead to mistaken interactions. A second type of correctness fault would result from one component losing visibility to another component because it was incorrectly nested within a third component. This type of fault is found by tracing connections between architectural components. Inappropriate nestings are identified because the execution trace crosses component boundaries that are unexpected or unnnecessary.
Have you ever participated in a design session where someone said, "Well, I am not certain about this, but lets put it in the model for now." To me, correctness is more important than completeness. I would rather leave the element out of the model until I am certain about its role than risk forgetting to return and correct or remove it. Our design documents always provide places for "issues" to be recorded. This is an appropriate holding place for pending design decisions. This prevents later arguments about whether a decision has been made about including an element in the design. If it is in the model, a decision was made.
A completeness fault is usually a missing connection or component. These missing elements may be discovered in a couple of different ways. Detailed tracing of use cases through the architectural model will identify elements that are needed to describe the scenario but that are not present in the model. A second approach to identifying missing elements is to examine those elements that are present. Consider the concept being modeled and use domain knowledge to identify behaviors that are missing. These are the two classic approaches to modeling so they are natural as two approaches to validation. The difference between the two is that the use case approach provides a systematic approach (so you know when you are through) while the modeling approach does not provide a definitive algorithm.
An architecture can be overly complete. As mentioned above, there may be connections between components that should not exist. There may also be components that should not exist. It seems that software engineers will often address a problem for which they have no good solution by encapsulating the responsibility for the problem in an object. An object-oriented "to-be-determined"! These component are hard to remove in later versions of the architecture but they sometimes introduce needless dependencies. Therefore, in addition to finding what is missing while tracing through a set of use cases, components that contribute to no scenario should also be noted and considered for removal.
One type of consistency fault is illustrated in Figure 1 where a connection present in the message sequence chart is missing in the package diagram. The multiple diagrams used in most design methods provide the opportunity for inconsistency. Many times these inconsistencies are simple errors where a developer has forgotten to update a model. Some of the inconsistencies are signs of the multiple diagrams doing their job: providing different views to more fully describe the solution. Another type of consistency fault would be evidenced in a class diagram by two paths over which two objects can communicate. This is an example of a potential fault. By that I simply mean that occasionally this is an acceptable design, although normally it is not. The double path fault becomes an actual fault if the two connections between components define different levels of visibility.
The team that tests the architectural model should include a systems engineer, application developers and architects. The role of the system engineer is to ensure that, in addition to the current requirements, pending changes to the existing requirements as well as enhancements being considered for future versions are considered. The application developers, as consumers of the model, provide the critical perspective that searches diligently for faults that will corrupt their designs. The architects, as authors of the architecture, provide clarification and detail when required and accept and analyze the results of the tests.
Architectural test cases are derived from the use cases that specify the system being developed. The tests can be conducted by identifying the use cases to be used and then constructing a message sequence diagram for each use case. The domain algorithms described in the use cases should be made possible by connections between components in the architectural model and the behaviors assigned to each subsystem. A test execution is performed by constructing a message sequence chart for a use case. As each message arrow is added to the diagram, a check is made of the architectural model to determine that there is a connection between the packages being connected by the message. The portion of the architectural diagram that is used for the test case is also examined for cycles. Finally, the cumulative coverage of the diagram over the set of use cases provides evidence for the completeness of the architectural model.
The test cases for the architectural model also evaluate the objectives the architecture is to achieve. One specific objective that is often investigated is the extensibility of the architecture. Extensibility can be specified by the declaration of change cases[1]. These descriptions of future requirements and potential directions of development are expressed in the use case notation and augment the application’s use case model.
The Model-View-Controller (MVC) architecture illustrated in Figure 1is used to provide extensibility from the perspective of adding additional views to the user interface. The testing process for this type of objective is very much like the technique for the use case model. Message sequence charts are constructed for the change cases. For the MVC architecture, a change case might be to support a spreadsheet view of data that is already being summarized in a report format. Unlike the use cases, we don’t expect to have already identified all of the objects needed for an implementation of the change case. Rather we are more interested in identifying inconsistencies that would be introduced by the change cases, such as a need to retain a complete set of data. This exploration can be used to expand and generalize the architectural model before much development is based on the model.
These architectural test cases may be automated if the model has been described using an architectural description language (ADL) such as Rapide[ 12]. Our research work at Clemson University is exploring the combination of this approach and the PACT testing architecture[7]. Correctness is observed by examining the answers from the executions of the test cases to be certain the results are as expected. Completeness is evidenced by the presence in the representation of sufficient components to represent the test cases. Consistency is, as always, more difficult to identify. The ability to write a single test case in two ways is one indication of a potential fault.
The architectural model "passes" this test when all of the high-level use cases can be mapped onto the architectural model. That is not to say that every object in every use case must find an equivalent in the architecture. The level of the architecture dictates that a use case may involve a number of the components in the architecture but several design level entities will be encapsulated within a single architectural artifact.
Coverage by the test cases can be measured in terms of the percentage of connections that are traversed by the use cases. I usually maintain a copy of the architectural diagram on which I mark each connection as it is involved in satisfying a use case. Typically minimal coverage would use every connection on the diagram. This does not necessarily give a good basis for evaluating completeness. In this case coverage must be measured in terms of the inputs rather than the model under test. If 100% of the use cases are tested and the model supports all of the cases, the model is complete.
The possibilities for architectural tests extend along a continuum from testing a completely manual model using a team of developers to testing a fully automated model using scripts. The approach taken for testing depends on how the model is being created by the development community. If, for example, the team is using Rational Rose, certain checks for consistency are available in the tool. We have implemented our own additional checks using the tool’s scripting language. However, scenarios represented in interaction diagrams can not be executed automatically as they can be in tools such as ObjectTime[10].
A digression
In a previous column I have described the modifications that Software Architects makes to the typical use case description[6]. We add three fields to the typical use case format:
These can be used for a number of purposes including assisting in the selection of tests. Each of the model testing techniques that I have defined so far can take advantage of this information to more accurately focus on faults in those areas of most importance to the project. For example, if we are most concerned about the overall reliability of the product, we would be interested in the most frequent uses of the system and being certain that they execute successfully. If we are most interested in safety, we would be most interested in the high risk use cases.
Application design model
The design model for an application consists of several types of diagrams. The UML notation defines the
Each of these diagrams is giving a view of the system under development but from different perspectives that emphasize different relationships. I won’t detail each of these here. Martin Fowler [3] provides a readable overview of the diagrams. Last month’s column described some aspects of the cross-validation of a set of these diagrams at a syntactic level. This month I will focus more on the semantics of the design.
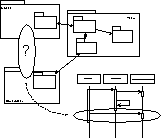
The goal of the design model is to provide sufficient detail, through the aggregation of diagrams, to guide implementation of the system. This model is derived from the application analysis model and is intended to comply with the constraints imposed by the architectural model. The model will involve representations of both classes and objects depending upon the diagram. The connections will signify all of the basic relationships between classes as well as messaging between objects.
|
Figure 2 |
|
|
The design model is the most detailed of the symbolic models. As such the model contains the most information, the largest search space and potentially the largest number of faults. Lets consider some of these faults and how we might detect them.
Correctness in a design model has two dimensions: domain knowledge and design principles. The design model may incorrectly represent specific facts or relationships that exist in the domain. It may also violate accepted design principles.
A project should have a well-specified set of design standards against which to evaluate the correctness of the model. This may come from adopting a widely used approach such as Bertrand Meyer’s Design by Contract[8] or the Law of Demeter[5] where time and experience have matured to the point that the approach is complete and self-consistent. Large projects or development organizations that manage a number of projects will often create their own design standard by adopting portions of known approaches and adding their own touches. Some thought needs to be given to ensuring that such a "hybrid" technique has sufficient expressiveness.
Lets consider a widely accepted design rule.
A class does not know about any classes that inherit from it.
First, translate the design guidelines into a design review checklist such as the one in Figure 3 that includes additional rules. Second, conduct a systematic read through the code searching specifically for violations of the rules. As an alternative, use a tool like CodeWizard [9] that automatically searches for violations of the design rules defined in Effective C++ and More Effective C++, both by Scott Meyers. This is a useful and versatile tool. It provides a set of rules for a specific language. Individual rules can be turned off and additional rules defined locally and added to the search. The design checklist provides a more flexible, albeit more resource intensive, means of guiding the code review. In the case of the example rule, a search of every inheritance hierarchy will determine whether any class contains a pointer to or creates an instance of a class that inherits from it. Again this type of rule can be automated in Rational Rose using the scripting language.
For a concurrent or distributed system, actual execution of a system does little to prove correctness. There are many variables interacting and two executions of the same code may not be identical in very important ways. A symbolic execution may actually be more effective at identifying particular faults. Faults such as:
can be found by a detailed scenario run by experienced developers. A detailed code review might find these problems as well, but often critical cases are missed if the systematic search is not performed.
|
Figure 3 Design Review Checklist |
|
|
Design rule |
Passed? |
|
No class contains a specific reference to an object from one of its subclasses. |
|
|
Every concrete class inherits from an abstract class. |
|
|
Every public operation is necessary behavior for other classes. |
|
|
. . . |
An evaluation of the correctness of the domain knowledge represented in the model examines the results of the simulated executions. But the "results" are more than just the "answer" returned by the final computation. We are also interested in intermediate results and the paths taken to obtain those results. By having the oracle participate in the testing session, intermediate problems with algorithms can be identified. The most difficult task can be keeping the test session focused on testing. I recently participated in a series of design test sessions in which the domain expert was also the moderator of the session. There was a tendency for the moderator to digress and discuss with the developers what the problems were with the algorithms and how to fix them. This resulted in much confusion and little progress. Separating the tasks of testing and designing into two different meetings is more efficient and accurate. Having a moderator, who is trained in facilitating these types of meetings, is also more efficient.
The completeness of the design model is evaluated with respect to the model that was used to produce it and to the needs of those who will use it. Below I mention that two models might be inconsistent if one is an incomplete translation of the other. A model may also be incomplete if it does not contain the extra detail that should have been added to support the activities at the new level. For example, an analysis level class diagram will typically provide only the method signatures for the public methods of the class. When the design-level class diagram is constructed, it should contain the signature of every method the class will contain. These missing methods will be identified by tracing scenarios using methods in the classes to perform computations and by using the post-conditions on each method to determine the exact scope of its operation.
Other completeness faults include:
Consistency faults may occur within a single diagram or between two diagrams within the same model. The multiple diagram approach of UML is both its strongest and weakest points. It is a strength in that it provides an opportunity to use one diagram to validate another, but it is a weakness because information is represented in more than one place and this can lead to the inconsistencies. The class diagram contains method signatures. State diagrams and message sequence charts also use methods. One basic check is that every method in a state model is also in the class diagram. The same check should be performed for message sequence charts. This is a clerical task that can be performed by some development tools or by a non-development staff person.
Examples of other types of inconsistencies include:
I also find it effective to test for consistency between the model that was used to create the MUT and the MUT. This catches transcription faults and errors of omission. This is more than just a clerical task however. Entities will be added as each new, more detailed model is created; however, some old ones will go away as well. For example, a package diagram will have only a loose correspondence to a detailed class diagram. Knowing whether the correct correspondence has been achieved requires domain and development knowledge.
Test scenarios that will be most productive for this model are those that involve objects from classes as high in the inheritance hierarchy as possible. At this level simple details may not be incorporated into the model. Look for test cases that embody the domain algorithms as opposed to more primitive actions. These are more productive because finding a defect at this level actually improves the quality of every class below it in the inheritance hierarchy and thus covers a greater percentage of the diagram(s). This level is also more productive because the important states are usually those related to the domain as opposed to system infrastructure such as the user interface. Finally, it is productive to begin with classes high in the inheritance hierarchies because these test cases can be reused at lower levels as well. [4]
A minimal level of coverage can be achieved using the system-level test cases whose development was begun during the requirements testing process and further refined while testing the architectural model. These test cases will need to be even more completely elaborated to search the added detail of the design model. This additional detail results in more possible paths through the program logic, additional parameters and more detailed error handling all of which require additional test cases to test the model thoroughly. Any conclusions about the completeness of a model are contingent on the completeness of the test coverage. A very basic test suite will only support an inference of completeness at a similarly basic level.
Summary
The systematic testing of analysis and design models is a labor-intensive exercise that is highly effective. The technique can be made more efficient by a careful selection of test cases. Depending upon the selection technique, the faults that would have the most critical implications for the system or those that would occur most frequently can be targeted. The testing process can be made more efficient by systematically mapping the use cases into successively more detailed test cases. Each new level of test case adds information and examines more detail.
Defects identified at this level affect a wider scope of the system and can be removed with less effort than defects found at the more detailed level of code testing. The activities I described here work closely with the typical development techniques used by developers following an object-oriented method. By integrating these techniques into the development process, the process becomes self-validating in that one development activity identifies defects in the products of previous development tasks. Several of these techniques can be automated, further reducing the effort required.
Testing becomes a continuous process that contributes to product realization rather than a judgmental step at the end of the development process. The result is an improved system which ultimately will be of higher quality and in many cases at a lower cost due to early detection.
References
1. Earl F. Ecklund, Jr., Lois M. L. Delcambre Change Cases: Use Cases that Identify Future Requirements, Proceedings of OOPSLA’96, ACM, New York, NY, 1996.
2. Don Firesmith, Brian Henderson-Sellers and Ian Graham. The OML Reference Manual, SIGS Books, 1996.
3. Martin Fowler. UML Distilled, Addison-Wesley, Reading Massachusetts, 1997.
4. Mary Jean Harrold and John D. McGregor. Incremental Testing of Object-Oriented Class Structures, Proceedings of the Fourteenth International Conference on Software Engineering, 1992.
5. Karl J. Lieberherr. Adaptive Object-Oriented Software, The Demeter Method, PWS Publishing Company, 1996.
6. John D. McGregor. Planning for Testing, JOOP, February 1997.
7. John D. McGregor. Quality - Thy name is not testing, Journal of Object-Oriented Programming, March 1998.
8. Bertrand Meyer. Object-Oriented Software Construction, Prentice-Hall International, 1988.
9. Parasoft Corporation, CodeWizard User’s Manual, 1997.
10. Bran Selic, Garth Gullekson, and Paul T. Ward. Real-Time Object-Oriented Modeling, Wiley, 1994.
11. Mary Shaw and David Garlan. Software Architecture: Perspectives on an Emerging Discipline, Prentice Hall, Upper Saddle River, New Jersey, 1996.
12. Stanford Rapide Project. Rapide-1.0 Language Reference Manuals, Stanford University, 1997.