Developer’s TestBench
Instrumentation for Class Testing
John D. McGregor
Last month I discussed some fundamental concepts about object-oriented software and used these concepts to begin the construction of a framework that would guide the selection of test cases. This month I want to totally shift directions and offer something for those of you who want to get your hands on some code. In this column I will present a technique for instrumenting individual classes so they can be tested.
The context for this discussion is a distributed system. Although the software presented here was constructed using the Java RMI model [5], the instrumentation technique is independent of the distribution model. The prototype software that I will discuss automates the instrumentation process making the technique feasible for a developer to use at their workbench during the development process.
The developer’s TestBench organizes the principal elements needed by the developer for testing components as they are constructed. The PACT classes, tools to instrument the classes and testboxes, (similar to the BeanBox for JavaBeans). In a previous column I presented the Parallel Architecture for Component Testing (PACT)[2]. PACT is an organizing architecture for test cases. The prototype tool that I will discuss in this column instruments individual classes. Another concept that I will discuss in a future column is the TestBox that provides an execution environment for the tests defined in the PACT classes.
|
Developer’s TestBench |
|
|
I want to first talk about the types of faults for which we are searching. Then I will present some techniques for finding those types of faults. Finally I will describe how the instrumentation helps in this search.
Faults in Distributed Systems
Distributed systems introduce a number of interesting new types of faults. In addition, these systems can contain all of the faults usually associated with monolithic, sequential systems. I will focus on only those faults that are specific to distributed systems.
Infrastructure Faults
Infrastructure faults include network and remote system failures. The two primary types of network problems are network outages and network latency. Problems in the network are seen as program faults if these problems cause the application to halt execution in an abnormal way. That is, the application obviously can not prevent a remote machine from failing; however, it can be designed to anticipate failures and to find alternative sources of the functionality required from the remote server. The failure recovery code should be searched for faults just as rigorously as the main logic of the program.
Network failure can result in an application hanging and bringing the entire system to a halt. Operations that involve the network can handle this potential problem by setting timers and abandoning the operation if necessary. Partial or transient failures can also cause difficulty. Communication layers may guarantee the delivery of individual messages, but a sequence of method invocations may not arrive in the order anticipated in the object’s design.
Network latency is the amount of time it takes the network to pass a message from the sender to the receiver. Latency between two specific points can vary widely over the span of a day, week or some other period. Obviously this variability can cause confusion when a test is executed repeatedly and different results are obtained over time. Applications can be designed to handle latency and system failure problems. For example, network browsers handle network latency by timing any attempt to connect to a remote server. If the connection is not completed within a specified time, the browser aborts the attempt and displays a message to the user through a dialog box. However, the browser continues to operate and allows the user to select another URL.
Concurrency Faults
Concurrency faults cover problems resulting from the synchronization of multiple independent tasks being interwoven by the operating system. These can result in deadlock, livelock or incorrect results due to race conditions. Essentially these are problems of order. Deadlock, for example, results from a conflict between the order in which two threads of computation are designed to obtain the same locks and the timing with which the locks are obtained. Race conditions are evidenced by sporatic incorrect/correct results.
All of these types of faults share one characteristic; their occurrence is non-deterministic. That is, the fault does not appear during every execution of the application, even if the program receives the same inputs. This obviously makes them difficult to detect, debug and repair.
Distribution Faults
Distribution faults include problems such as required objects not being registered, servers not implementing a requested operation and incorrect permissions on remote machines. One project on which I was consulting developed a multi-layered design for initializing the system. This ensured that objects that needed to lookup other objects in the registry waited until the appropriate phase of initialization when the target objects would have been registered. The object hierarchy (levels of encapsulation) makes the design of these schemes a natural part of the system design.
Dynamically loadable files, whether in a distributed system or not, have added to the complexity of the execution environment. If a system is distributed across several machines, there is a much greater likelihood that the permissions on some file that is needed will be incorrect. For this and other types of faults in a distributed environment, the problem may be compounded by the fact that error messages may appear on the console of the machine where the error occurs rather than on the machine where the user of the system is located.
For the remainder of this column I will focus mainly on concurrency faults.
Finding Ordering Faults in a Distributed System
Several of the categories of faults described in the previous section are related to the order in which events occur. Latency on one branch of a network can cause messages to arrive at a server in a different order than was anticipated. Concurrent threads will be interwoven in different sequences with almost every different execution. One key to finding faults in distributed software is to investigate the effects of varying the sequence of events on the target object.
Most distributed software is sufficiently multi-threaded for the number of paths through an application to be too large to construct a good structural test plan at that level. This emphasizes the need for a comprehensive class-level testing process. I will limit myself to that scope for this column. By beginning at this level, faults will be more localized. They will be more likely to be repeatable during subsequent executions and even identifiable during a code review.
As I stated above, many concurrency faults are basically problems of ordering. For example, a concurrent design often assumes that the outcome of a code segment will be the same no matter which of two threads arrive at a synchronization point first. If the behavior does change depending upon which thread reaches a point first then a race condition exists and will lead to faulty behavior. Executing the software so that each of the two orderings occurs verifies that the concurrency is correct. This testing can be achieved in several ways.
Instrumenting Classes
The objective of the technique that I want to present is to support class testing and in particular to give the tester reasonably fine-grained control over the interactions that occur between the test cases and the object under test (OUT). This control is gained by reflecting on the interface of the OUT to automate the production of a test menu and then allowing the developer to invoke individual methods. A secondary objective is to avoid modification of the production software. This can be accomplished using a wrapper design pattern.
The wrapper pattern supports the addition of behavior to, or the replication of, behavior from the encapsulated object. The pattern involves at least two objects: the wrapper object and the wrapped object. For my purposes the wrapped object corresponds to the OUT. The wrappers come in a variety of "flavors" including RMI and CORBA [3]. Each wrapper template contains infrastructure specific behavior. This includes being able to register names and being able to capture the standard exceptions thrown by the distribution system..
If the class under test (CUT) is a server, it provides an interface to its clients. In a distributed system, a server is made available through some type of naming service that allows clients to locate the server (in this case the OUT). The wrapper around the OUT must still provide that interface and be available through the naming service (although it may/may not need to be under the "expected" name). The interface of the OUT is a subset of the interface of the wrapper object. This allows the replacement of the OUT by the wrapper. In this way the impact of instrumenting the system is minimized because the other objects see the wrapper as the OUT.
The wrapper pattern is particularly powerful when implemented in a reflective language such as Java. The wrapping tool begins with a "template" wrapper. It reflects on the interface of the CUT and adds that interface to the test template. Reflection is also used to integrate the PACT class for the CUT into an interactive environment, an ObjectBrowser.
The test template includes an interface that supports testing behaviors. The interface includes methods for manipulating logs, for controlling hardware that must be available to the OUT, and for interfacing to other software packages such as packages for complexity analysis.
A Process and a Tool
We have created a variety of prototypes for this technique. These tools automate part of the process of instrumenting and testing the CUT. I want to describe the process step by step by focusing on one of the tools, implemented using Java’s RMI approach. This implementation uses the [4]ion API of Java.
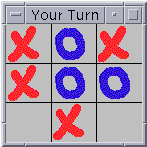
As I describe the process I will illustrate with an example. The example is a distributed implementation of the Tic Tac Toe game. The interface that is presented to each of the two players is shown in Figure 1. Each player can see their moves and those of the opponent.
|
Figure 1: Tic Tac Toe Interface |
|
|
Context: The developer has created a class as part of a distributed system and wishes to test it. It is not practical to stub all of the calls to other objects in the system. Therefore the object will be tested in its operational context; however, the process steps will focus on the CUT.
1. The developer uses the Wrapper to automatically create a wrapper class (WCUT) that includes in its interface the interface of the CUT. The Reflection API is used to obtain the interface of the CUT and it is copied into the wrapper class definition. Objects instantiated from the generated wrapper class will each encapsulate an instance of the CUT. This component is a Java program that runs without interaction:
java Wrapper Player.java
2. The system (or some subsystem) is deployed, across multiple processors perhaps, as it would be in a production environment. The OUT will be replaced with its wrapped counterpart. The wrapped OUT (WOUT) will be registered with the registry under the name expected for the OUT.
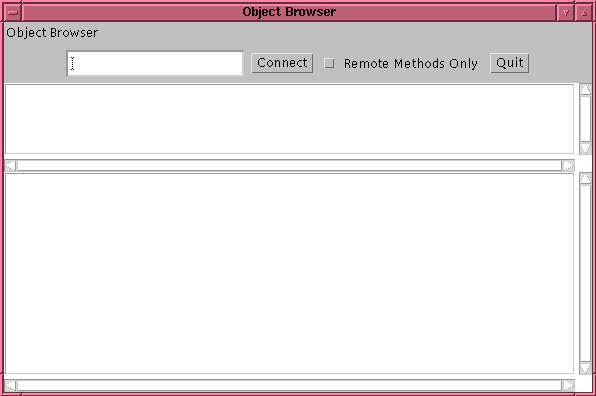
3. The developer then uses the ObjectBrowser, shown in Figure 2, to monitor and control the WOUT. The ObjectBrowser first presents a list of all of the objects registered on a particular registry. In RMI this is partitioned on a processor by processor basis. The browser lists all of the objects registered on the machine to which the developer connects. A CORBA implementation would mask the exact location of the WOUT from the developer.
|
Figure 2: ObjectBrowser Interface |
|
|
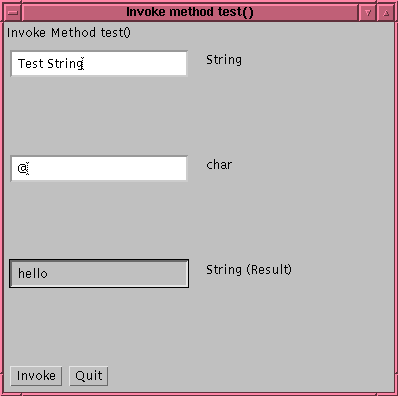
4. The developer selects an object to work with. (Preferably the WOUT). When the object is selected, the interface methods are listed. The developer may then select any of the methods to invoke. A dialog box , shown in Figure 3, is displayed with a field for each of the parameters to the method. The developer provides a value for each parameter and the method is invoked.
|
Figure 3: Method Selection Window |
|
|
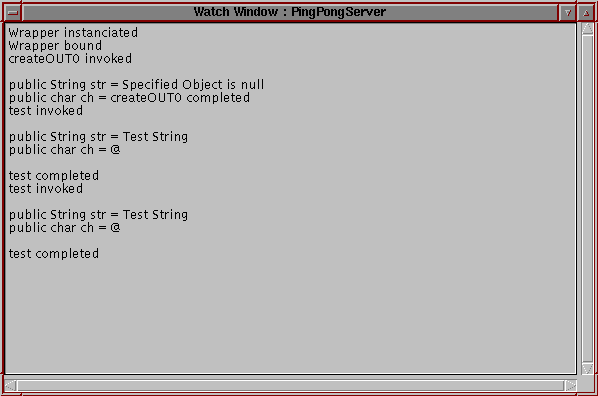
5. The return value if any is displayed. A Watch window, shown in Figure 4, presents the values for the internal object state via the Reflection API. (Currently, the private state of a Java class can not be directly accessed. This hopefully changes with Java 1.2) The developer verifies that the actual behavior meets the specification.
|
Figure 4: WatchWindow |
|
|
6. The developer invokes methods more or less at random in the initial phases of development. As development proceeds the developer should become more systematic and execute a complete protocol (a sequence of messages that implement some meaningful behavior) rather than just isolated methods.
A couple of notes about the process. (1) The developer is responsible for following the sequence of method calls that will lead to correct operation. That is, the developer can invoke a method whether or not its pre-conditions have been satisfied. If the pe-conditions have not been satisfied, the correct behavior of the object is unspecified. (2) This process can be applied to a single object without the rest of the system.
Coverage Criteria
Carver and Tai [1] defined a coverage criterion for concurrent software that provides a starting point for distributed software in general. They identified those points in the software where multiple threads must synchronize. A synchronization path then was a set of statements that lead from one synchronization point to another. An acceptable level of coverage was the execution of all of these paths. This is not necessarily an easy requirement.
Given that I identified ordering as a critical , a coverage criteria that measures this attribute is in order. Carver and Tai executed a large number of test cases to increase the probability that different orderings of events were covered. Where possible, I believe in using this class level testing process to more systematically provide this coverage. One technique obviously is for the developer to specifically send messages to the WOUT in differing orders. However, when this is insufficient I have used the wrapper to introduce artificial delays. The WOUT forwards those messages to the OUT that are part of the OUT’s interface. By delivering the message on a separate thread and delaying the delivery until another specific message is received and forwarded provides systematic coverage of the possible orderings.
A common sense coverage criterion is that all necessary pieces of the infrastructure should be exercised by some test case. For example, both RMI and CORBA implementations provide means of improving the efficiency of connections. If a server is local to a client, the stub/skeleton infrastructure is bypassed. So testing the interactions between two objects only on one machine does not exercise an important portion of the infrastructure. I will say more about this in a later column when I address more issues about testing distributed systems.
Now the bad news
The most obvious bad news is that the process is not totally automatic. One of the problems with testing objects is that often they require other objects as parameters. Once you are beyond primitive types, providing parameters for method invocation is not easy. For each class that is to be used as a parameter a Helper class must be created. This process is made simpler by using inheritance to specialize an abstract definition (templates are another possible approach) but it still requires additional effort. A new step is added to the process:
0.5 The developer creates a Helper class for each class that will be used as a parameter to a method of the CUT. This only needs to be done once and can be reused for testing any classes that require this class of parameter.
The other bad news is that with versions of Java before 1.2, private attributes and behaviors can not be reflected upon. The good news is that supposedly version 1.2 will provide security permissions that provide a means of accessing private information.
Conclusion
The complexity of the interactions within a distributed system makes class testing essential. This is most easily accomplished in the context of some portion of the system. In order to validate the tests that are executed, the CUT is wrapped within another class that presents the same interface as the CUT to the remainder of the system. The PACT approach is used to validate the correctness of the state within the object under test. This is a safe technique because the objective is to test the class not the remainder of the system. The behavior of the system that incorporates the WCUT will be changed but this process is not intended to ensure correct system operation. The result is a tested class that will not need to be changed after the test session to remove test-related behavior.
The code for the RMI prototype is available for non-commercial use by downloading from: TBA. Improve it, use it and let me know what techniques work!
Acknowledgements
I owe special thanks to Allwyn Pereira for his hard work on the software described in this article. We also acknowledge the foundation work of Chuck McManis whose Java One presentation provided the basis for the RMI prototype. His software, without our tinkering, is available from the Java One home page.
References