Figure 1: Cumulative Defect Data

Making Component Testing More Effective
John D. McGregor
Last month I presented a high level view of a component test method. This month I would like to consider how we might evaluate the effectiveness of the test method. I will do this by integrating the test method within the context of a general software development method that emphasizes process improvement. In that context I will discuss making component testing more effective. I would also like to extend the discussion from last month to include some additional techniques and tools. These tools will relate the test method to the other methods being used on the project.
Personal Software Process
The Personal Software Process (PSPSM ) was developed by Watts Humphrey at the Software Engineering Institute (SEI)[Humphrey]. This is a process definition for the work of the individual software engineer and is designed to be complementary to organizational-level processes such as the Capability Maturity Model (CMM)[Paulk]. Like the CMM, PSP is defined in layers that increase in rigor at each level. The PSP defines processes that guide the individual engineer in addressing most of the Key Process Areas (KPA) of the CMM. The PSP divides the software development process into a sequence of phases including a Test phase in its traditional place, following the Compile phase. In this column we will also refer to the "testing" activities that occur in each phase (e.g. design reviews, code inspections).
The PSP defines a set of data that are collected by the individual software engineer about their own work. The PSP also defines a set of metrics that are computed from this data. Each successive layer of the process definition specifies additional data to be collected and metrics to be calculated. Some of the data specified in the process are shown in Table 1 (I will focus on the data that is most closely associated with testing). One metric that PSP defines is the Number of Defects Found in Test/KLOC. This is computed as:
1000*(test defects)/actual LOC
For evaluating the testing phase of the development process, the larger the value of this metric the better because we are finding faults that would remain in the product otherwise. Considering the validation activities within each development phase, a large value for Test Defects/KLOC indicates that these activities are not sufficiently effective. Defects are escaping these activities and "living" to reach the testing phase. A number of other metrics are also defined that measure various aspects of the quality of the development process.
|
Table 1: PSP Data Items |
|
|
For each defect: |
|
|
the type of the defect |
|
|
phase at which the defect is injected |
|
|
phase at which the defect is removed |
|
|
time required to fix the defect |
|
|
For each phase in the process: |
|
|
estimated time in the phase |
|
|
actual time in the phase |
|
|
number of each type of defect created here |
|
|
number of each type of defect removed |
|
Companies that have used the PSP report an improvement in the quality of the product they are producing[Ferguson]. They also use the aggregated personal data collected to improve the corporate software development process. The data are not used to evaluate individual developers!
Defect Models
A defect model consists of two components: a defect classification scheme and the actual distribution of defects within the categories of the scheme. The defect model provides a classification of the types of defects that are found in the software. The PSP uses a simple 10 point classification scheme, shown in Table 2, to categorize defects.
|
Table 2: PSP Defect Types |
|
|
10 - Documentation |
60 - Checking |
|
20 - Syntax |
70 - Data |
|
30 - Build, package |
80 - Function |
|
40 - Assignment |
90 - System |
|
50 - Interface |
100 - Environment |
|
Figure 1: Cumulative Defect Data |
|
|
The second element of the defect model is the relative frequency with which each type of defect occurs. This information can be accumulated over several projects within the company or it may be only for your current project. Figure 1 is one graphical representation for this portion of the defect model. This information can be used in the testing process to assist in selecting test cases. If the tester knows that historically the company’s development process results in a large number of occurrences of a specific type of defect, then the tester will select more test cases directed at this type of defect.
Process Improvement
Each method and process that is used in a project should be examined periodically in order to improve what is done and how it is done. These examinations will be more useful if there are specific quantitative measures that guide the task. In this section I will present some specific methods for collecting that data. In PSP these data are collected at the individual developer level and used to analyze personal performance. These individual data sets can then be integrated to support team or project level analyses.
Collect Data
Any significant change in a process should be based on data that has helped identify the problem. Data collected subsequently should validate that the change has been successful. Basili’s Goal-Question-Metric (GQM) technique is useful for guiding the process of determining what data to capture and what metrics to compute.[Basili]. For our process improvement purposes we have the goal of modifying the process so that fewer defaults are present in the product. To measure whether we are achieving that goal we might ask two questions. How many defects are being created? Where are the defects being created? The metric associated with the first question is obvious and the results of that query have already been shown in Figure 1.
Table 3 shows a simple table that a developer can use to record defects as they are found. Just like those pesky records the IRS wants consultants to keep, this recording will be most accurate if it is done contemporaneously. The column labeled Injected during is used to estimate when the particular type of fault was made. For example, if a method does not carry out all of the functionality that it should the problem is more likely to be a design defect than a coding defect. This information can be used to answer our second question. Certain types of defects will most likely be created in certain development phases and a pattern usually quickly emerges.
The Removed during column is used to record the phase we are in when the defect is detected. Obviously this value can be determined exactly. Either while recording the defects or during analysis the Fault description is used to determine the fault category.
|
Table 3: Fault Data Collection |
||
|
Fault description |
Injected during: |
Removed during: |
|
method missing |
Design |
Design Review |
|
; missing |
Code |
Compile |
|
= used in place of == |
Code |
Test |
|
… |
||
Analyze Data
Collecting large amounts of data does little by itself to improve practice. The data must be organized so that it can be analyzed and used as the basis for understanding. One technique for organizing the data is to group the data based on when the fault was injected into the product. This is logical and necessary but not sufficient. There will probably still be too much information. The graph in Figure 1 illustrates the use of the simplified PSP defect categories to reduce the data to information.. This is a useful starting point for establishing a baseline. As the analysis becomes more detailed, a more detailed classification such as the one published in [Beizer] can be used to help pinpoint more exactly the types of defects being injected.
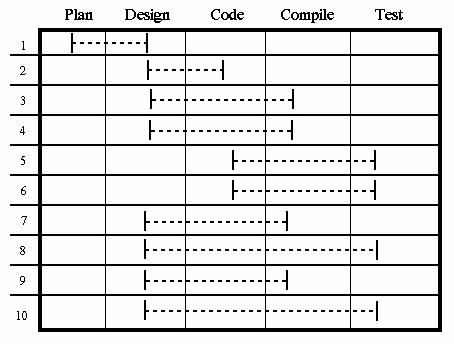
Figure 2 summarizes the "live range" for defects injected at specific phases. Any phase from which a defect escapes is a failure of the testing activity for that phase. An objective of the testing process is to reduce the length of these ranges as much as possible.
|
Figure 2: An example of live ranges for type 50 defects |
|
|
Patterns for Improvement
Adopt procedures that will identify the types of defects that are being created in each process phase.
The PSP defines a process divided into the fairly conventional phases of Plan, Design, Code, Compile and Test. Yet in each phase we wish to consider the possibility of identifying the presence of defects, not just in the Test phase. To achieve this goal, I view each of these phases as containing a set of activities. The activities include Planning, Building and Validating. For the Design phase of the PSP there would be an activity in which we plan the design, an activity in which the design is built and one in which the design is validated.
Testing may be driven by several different criteria. The most common approach is coverage driven. That is, test cases are selected to achieve the execution of every branch of every conditional statement or the execution of every statement or some other measure of the extent of execution. A second possible approach, often used in system testing, is to use an operational profile to guide test case selection. In this approach parts of the system are tested more thoroughly because in practice that part of the system is used more often. The alternative described here is to select test cases based on the types of defects that are thought to exist in the system. Obviously some defects are not dynamic and do not cause faults during execution. No test case selection strategy will identify these defects.
By examining the data available from the defect identification procedures, I can identify the types of defects with the longest live ranges and focus on correcting the testing activity in the phase that originates that type of defect. For example, from the data shown in Figure 2, a large number of Interface defects are being created in the Design phase and not being detected until the Compile phase. This points to problems with the testing activities during the Design and Code phases. This leads to the need to …
Improve the testing process by adding or improving testing activities that should find the defects that are currently escaping attention. Two techniques can be used here. One is a design review. A review is a detailed examination of the design that is directed by a checklist, a list of desired outcomes against which the design is checked. The checklist should contain three types of outcomes:
- The class specification contains no public attributes;
- The design contains no dependencies on proprietary hardware; and
- The design appropriately handles all many-to many relationships.
A second technique is the use of a design model testing process. I will expand on this idea in a later column, but for now I will give just a brief overview. The model testing technique is similar to a review or inspection but differs in that specific test cases are used to systematically search the design. The model testing technique uses test cases that are similar to those that will be used during system testing, but they are structured according to the formality of the design. If the design is an executable model, the test cases are written in an executable form. If the model consists of only paper diagrams, the test cases need only be textual scenarios that are used to hand check the model. The exact test cases that are used are selected to reflect the priorities presented by the defect models.
The benefits of using this testing approach is the ability to do a systematic examination against the system requirements. The design review process will examine what is in the model carefully but will not cross-check the model against what should be there. However, it is preferable to …
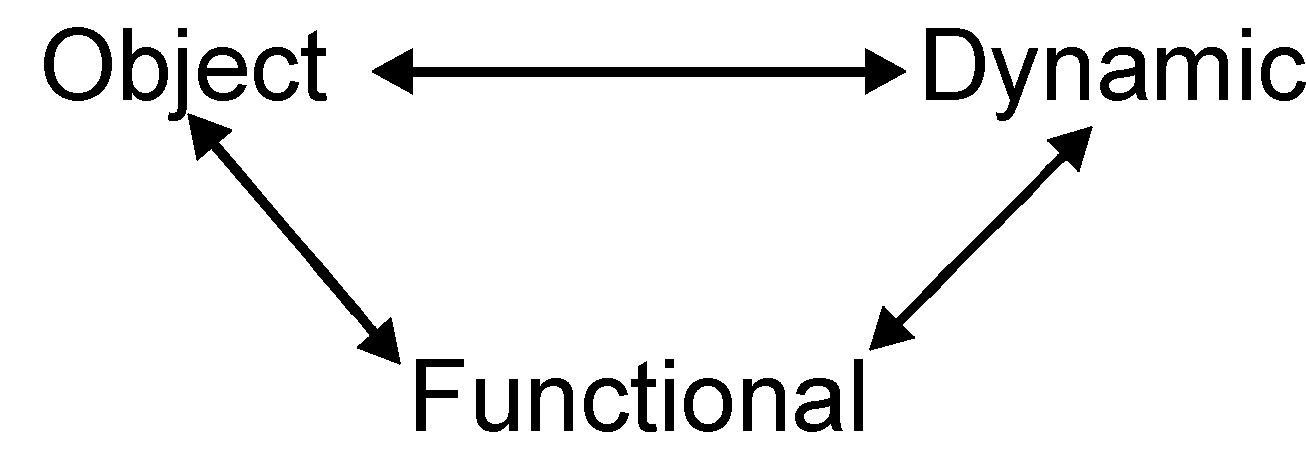
Institute design practices that focus on preventing the types of defects that are being found in order to reduce the number of defects being injected during design. Ideally defects shouldn’t have to be removed, they should not happen. During the Build activity the practices followed by the engineer should be sufficiently constrained that errors become obvious immediately so that they can be corrected immediately. By utilizing cross-validating models, in which the construction of one model actively identifies problems in the other representations, defects are less likely to occur. Multi-view models, such as the set illustrated in Figure 3, used by many analysis and design models provide the cross-validating property if we will take advantage of it. For example, the message sequence chart for a specific algorithm in the system integrates several objects from multiple classes. Most of the messages will be from one object to another. As these messages are added to this functional model, the developer should check that the message is matched in the object model by associations between the classes.
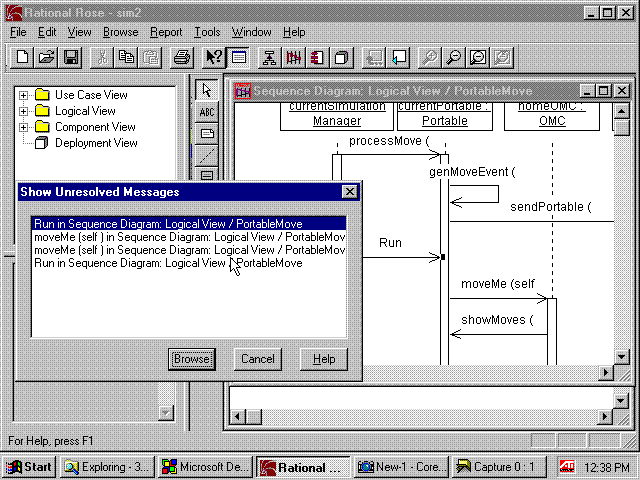
The use of specific tools may support this defect prevention pattern. Rational’s Roseä , for example, maintains a central design database. If the engineer enters a message in a message sequence chart, for which a corresponding method does not currently exist in the specification of the receiving object, Rose allows the user to create the method. This type of real-time consistency checking provides valuable feedback to the tool’s user. Figure 4 shows the inconsistency report that can be run at any time during model creation. The report guides the developer to those parts of the model that require attention.
The checklist discussed above is also a good training tool to reduce the number of defects injected into the product. As engineers periodically review their own work using the items on the checklist, they become more aware of these basic principles and actually think about them as they design rather than as an afterthought. Figure 5 shows a short checklist that addresses a number of common design problems.
|
Figure 3: Cross-validating models |
|
|
|
Figure 4:Inconsistency report in Rose |
|
|
|
Figure 5: Design Review Checklist |
||
|
Criteria |
Yes |
No |
|
Every message on a sequence diagram corresponds to an association in the object model |
||
|
Every transition in a dynamic model corresponds to a message in the interface of a class |
||
|
Every object in a sequence diagram corresponds to a class in the object model |
||
|
Every sequence of messages between two objects satisfies the pre-conditions of the methods invoked. |
||
|
Every path through the dynamic model satisfies the pre-conditions for the methods that enable the transitions |
||
Summary
A complete process definition should include an activity that guides efforts to improve the process. Process improvement should provide data to support the improvement of every phase. One type of data are the defects that are injected into the product. Analyzing where these defects originate and where they are identified determines a range of development phases in which improvements are required. Several simple tools and techniques can be used to collect and analyze data in order to modify activities and to later evaluate the degree to which the process has been improved.
References
[Basili] V. Basili and D. M. Weiss, A Methodology for Collecting Valid Software Engineering Data, IEEE Transactions on Software Engineering, vol SE-10, no. 6, Nov 1984, pp. 728 - 738.
[Beizer] Boris Beizer. Software Testing Techniques, International Thompson Publishers, 1990.
[Ferguson] Pat Ferguson, Watts S. Humphrey, Soheil Khajenoori, Susan Macke and Annette Matvya. Introducing the Personal Software Process: Three Industry Case Studies, Hand-out in Train-the-Trainer PSP course, SEI (Accepted for publication in IEEE Computer).
[Humphrey] Watts Humphrey. A Discipline for Software Engineering, Addison-Wesley, 1995.
[Paulk] Mark C. Paulk et al. Capability Maturity Model for Software, CMU/SEI-91-TR-24, 1991.