Figure 2: Bridge pattern
Testing from Specifications
John D. McGregor
I have previously referred to two types of techniques for constructing test cases: specification-based and implementation-based. I have also discussed that a complete test plan should include some tests developed from each of these perspectives. In this column I want to discuss criteria for evaluating specifications and how the quality of the specifications affects the quality of tests.
My neighborhood video store has a great security system. They identify customers by their telephone number. When you bring a movie to the counter to rent, you are asked for your telephone number. I noticed very quickly the flaw in the system. One of the clerks enters the provided telephone number, looks at the screen for a moment and then looks up and asks, "Your name please?" Obviously she is going to test the specification of what your answer should be, as shown on her computer screen, against what your answer actually is. However, another clerk uses the system very differently. She asks for the telephone number, looks at the screen and says "McGregor, right?" Only an honest person would, at that point, say no if that isn’t correct which defeats the purpose of guarding against dishonest people. The clerk is following the practice of many developers, building the test from the product rather than the specification.
When I give tutorials to testers and mention constructing test cases from specifications, someone always recounts a tale of having to deduce the specification from the code in order to build tests. The obvious danger is that the tests will determine only whether the code does what it was programmed to do and not whether it does what it should do. This is the danger of implementation-based tests and it reminds us of why there should also be specification-based tests.
What is a specification?
Simply put a specification is a description. It is a description of some thing. The thing may exist already or it may not. Some specifications are more complete than others. I might specify that my new car is red. This would tell you how many speeding tickets I am likely to receive but it does little to tell you how large the car is or whether it is a rear wheel or front wheel drive car. On the other hand if I write more pages in the specification than there are in the owner’s manual then I probably am overspecifying.
The quality benefits of separating the specification of an object from its implementation are well known in software engineering. I recently overheard someone say, "of course you can’t separate the specification of a Java class from its implementation the way you can in C++ because everything must be in the same file". This totally misses the point! Having the class information in two separate files, as in the .h and .c files of C++, is not the intent of the separation and may in fact detract from the quality of the product. It is maintaining an independence between what the object is supposed to do and how it is supposed to do it that is important. C++ interface descriptions that expose the types of data members are poor specifications whether or not there is physical separation .between the code that declares the method and the code that defines its details.
The two specifications in Figure 1 show the difference between exposing implementation details and exposing only those details that should be known by the object’s clients. Figure 1 (a) exposes the fact that the list is composed of ListNodes. Figure 1 (b) only exposes the fact that the information stored in the list is of type ItemType, which an client should already know.
|
Figure 1: Exposing the implementation details in a specification |
|
|
(a)
class List{ …
ListNode removeFromFront(); … }
Returns a node which should not be known outside the list class |
(b)
class List{ …
ItemType removeFromFront(); … }
Returns the item stored in the list which must be known outside the list class anyway. |
From a reuse perspective one of the benefits of the separation is the ability to change the implementation of a class without changing its specification and those of the other classes that depend on the modified class. Today’s systems have added a new dimension: the capability of allowing these implementation changes to occur dynamically.
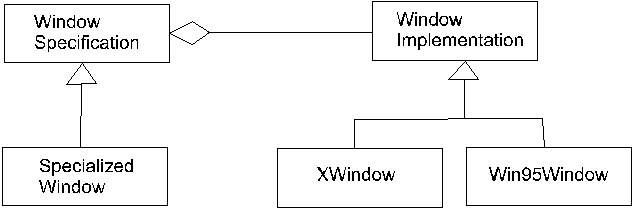
Consider the Bridge design pattern that supports this dynamic substitution[1]. This pattern, diagrammed in Figure 2, represents the specification in one class and provides multiple implementations through a family of classes. This pattern may be realized through a template class in C++ and the specific implementation class is determined at compile time. It may be part of the computation of the WindowSpecification constructor and the exact implementation class is determined at runtime. The diagram in Figure 2 illustrates the pattern using a cross-platform windowing system that isolates platform specifics in implementation classes while specifying the behavior in a specification class.
|
Figure 2: Bridge pattern |
|
|
One goal of testing is to determine whether the implementation of the product "satisfies" the specification. In order to achieve this goal the tests are constructed from information from the specification but without looking at the implementation. This impartiality is intended to ensure that the tests cover what the product is supposed to do rather than being limited to what the product can do. Of course the benefits of this approach are only realized if the specification is of high quality and exists!
Types of Specification
Defining exactly what something is can be almost as difficult as defining what we wanted it to be originally. There are two dimensions along which specifications can be constructed. The syntactic dimension provides static information while the semantic dimension provides more dynamic, behavioral information. Interfaces and protocols represent these two dimensions of specification that are commonly used for object-oriented components.
Interfaces
An interface is a specification of the operations defined by a class. In most languages, a single class can define multiple interfaces for each of its objects. A class has its own personal interface (usually referred to as private), this is used to specify those implementation details that should be known only within each object from the class. In many languages, a class has an interface that is accessible to its objects and to those of its descendants (protected), that is used to provide implementation details that may need to be overridden by the subclasses. Finally, the class defines an interface that all objects within the same scope can access (public). Each interface consists of the specification of the operations that implement the behaviors that characterize the class. For example, consider the portion of the interface for a Window class shown in Listing 1.
|
Listing 1: Window class specification |
|
class Window |
|
public: |
|
Window() throws xalloc; |
|
void show(); |
|
protected: |
|
int OnMouseMove(Event e); |
|
Decorator* scroller; |
|
private: |
|
MemoryBuffer* windowBuffer; |
Each method in the interface is specified through the types of its parameters and return values. (Yes, I said return values. Any exceptions thrown by the method are also included in the specification.) The interface provides sufficient information to judge whether a use of a method is syntactically correct.
What an interface does not specify are the semantics of each operation including the pre and post-conditions that describe the sequences in which the methods are expected to be called. Interfaces provide quick references for developers who are checking parameter types.
Protocols
A protocol is a specification for the interactions among a cluster of objects. The protocol adds a semantic dimension to the syntactic dimension provided by the object’s interface. The protocol specifies permissible sequences of messages that each object may receive. These sequences can be derived from the pre and post-conditions defined for each method. A method’s pre-condition defines the state the object should be in before the method can be called. Indirectly this determines those methods that must have been called before this method is called. The
show() method would have a simple pre-condition such as:
Pre-condition: The Window object must have been constructed and
the windowing system must be initialized.
A method’s post-condition is a description of what a method is supposed to do provided that its pre-condition was true when the method was invoked. The formality and completeness of the post-condition will determine how easily and accurately tests can be constructed. The post-condition specifies all possible positive outcomes in which a "correct" answer is computed and it specifies all error conditions that the object will recognize and respond to. The
show() method would have a post-condition such as:
Post-condition: The rectangular area defined by the upperLeft and
lowerRight points displays the contents of windowBuffer.
The third piece of the specification is the class invariant. The invariant is a statement that constrains the state of each object that belongs to the class. The invariant defines limits on the attributes of the object. For a Window object the invariant would state that:
lowerRight.x > upperLeft.x && lowerRight.y > upperLeft.y
No methods on the Window object can be allowed to violate these conditions.
A protocol defines the sequence(s) of messages that an object may receive over its life time. Some subset of these messages will be required to accomplish a specific task such as moving or resizing the Window. A protocol description functions as an object-level use case. An object may participate in any number of protocols with different sets of objects.
Some things can be said about sequences in general. For example, the basic protocol for an object must begin with the invocation of an object constructor. This is a basic requirement but not one that every compiler will verify. In Java the compiler will allow:
Window main;
main.show();
but, at runtime the result of these lines is:
java.lang.NullPointerException
Protocols play an important role in determining how easily two components can be made to interact. When decisions are being made about the (re)use of existing components, the ease with which the existing component can be made to participate in the necessary protocols is a critical factor in determining whether to use the component.
Evaluating Specifications
Before we use specifications as the basis for testing a product, it would be nice to have some confidence that the specification satisfies the requirements. There are a number of techniques and approaches for this, but they all revolve around three essential measures: completeness, correctness and consistency.
Completeness
is a measure of whether sufficient information is contained in the specification for the description to be unambiguous. It is judged by determining if the entities in the model describe the aspects of knowledge being modeled in sufficient detail for the goals of the current portion of the system being developed. The leading reason for specifications to be incomplete is that the requirements from which they are built are incomplete. (This points out the necessity for a process step in which the requirements are tested.) Incomplete specifications lead to incomplete implementations and testing.Correctness
is the property of producing the same result as an expert would in a given situation. The expert, referred to as an oracle, is generally considered infallible. In practice this is not always a valid assumption; therefore, our notion of correctness should include the possibility of a test being judged to have failed when it in fact passed. In the case of a specification, correctness is usually judged in comparison to the system requirements which are a stand-in for the a domain expert.Consistency
is a measure of whether there is agreement among all parts of a specification. For example, specifying a state but providing no specification of a transition to reach that state is inconsistent. Inconsistencies arise in a number of ways. The simple example below shows a common mistake:void setX(int);
long getX();
A focused, formal code review will find problems such as this one. The ability to detect this type of inconsistency is enhanced if the coding standard groups get/set method pairs as opposed to grouping all setters in one place and getters in another. This is an example of an internal inconsistency among elements within a single class specification.
Consistency can also be viewed from an external perspective among several class specifications. In object models, for example, we often provide a model showing relationships among objects at one level of abstraction and use a separate model to show objects at another level. Changes made to one of the models don’t always get reflected in the other model and an inconsistency is introduced. Rational’s Rose[2] produces an inconsistency report developed from scanning models and specifications in the database it keeps of all the model’s information.
Other criteria may also be useful. Conciseness which reduces the possibility of writing redundant tests. Clarity reduces the possibility of writing tests that misinterpret the specifications or the expected results. Additional criteria are chosen to validate the specific goals of a project.
The degree to which our specifications pass these measures can be evaluated in several ways. Design and code reviews often work at the specification level. Executable models can be created and executed using specific test cases. The results of executing these test cases, even the act of writing the test cases, will identify faults.
Impact of Specification Quality on Tests
The quality of the specification-based tests in our test suite will directly reflect the quality of the specifications from which they are constructed. The effectiveness of our testing process will also be affected. In this section I will consider each of the criteria described above and I will attempt to relate sufficient examples to support the "you can pay me now or you can pay me later" view that taking the time to write high-quality specifications will be offset by more effective and efficient testing ( not to mention that there will be fewer faults to be found).
Tests constructed from an incomplete specification will often fail when we expect them to pass because the implementer had to make decisions not covered by the specification. These decisions are not visible in the specification but none the less affect the result of the computation. Tests constructed from an incomplete specification will often pass when we expect them to fail because the invariant does not state all the necessary constraints on the object’s state. The result may be a program that has more functionality than is tested. This functionality may be used by other parts of the program and may cause major failures that are not recognized until the product is shipped.
One major area in which specifications are often incomplete is system-level actions that occur infrequently. The interface for Window in Listing 1 declares that the constructor may throw an out of memory, xalloc, exception. This will seldom be forgotten in writing the specification since allocating memory is a major function of a constructor. What might be missing from this specification is the fact that the
show() operation messages a system object that allocates a second buffer to improve performance of the screen drawing operation. Thus indirectly, show() may result in an xalloc exception being thrown and it should be shown in the method signature.
This example also illustrates another common "completeness" mistake, the failure to propagate exceptions from the called interface to the calling interface. After a presentation at a conference recently, a person came up and said "you aren’t really going to use the
throws clause in your specification?" When I asked why not, he replied "Because then you have to use it in all the methods that send that message." Precisely! If the compiler will catch those methods that do not list all the exceptions that might be thrown, the specifications can be modified and more compete tests can be created. Although many C++ compilers do not check this, it is an integral part of the Java language.
Tests constructed from incorrect specifications will not necessarily fail when they should if the specification is consistently incorrect. That is, the example given earlier about accessing
x could be written as:
void setX(int);
int getX();
But the value of the attribute being represented by
x may need to be sufficiently large to require a long rather than an int. If the developer follows the specification carefully, the unit tests of a component might succeed if the developer simply makes up test data based on the specified data type as opposed to the real domain values. These types of faults will not be identified until the system level tests apply real domain values to the class. This defeats our objective of finding faults as early in the development process as possible.Specifications often contain incorrect pre-conditions. Underspecifying will mean that the pre-condition does not define all of the constraints necessary for correct operation. Overspecifying will mean that the pre-condition constrains more than is necessary. Obviously overspecifying is safer than underspecifying; however, opportunities for reuse of a component may be missed because the pre-conditions are more stringent than can be guaranteed by the calling method.
Tests constructed from an inconsistent specification will often result in some tests failing without an apparent reason. The test is constructed by looking at one part of the specification but the implementation may have been developed from the contradictory perspective. The code will work correctly from the perspective of the developer but not from that of the tester. Object-oriented systems are less likely to have this problem since the specification for a class is quite localized.
The Bridge pattern, shown in Figure 2, provides an example of how inconsistencies are easily introduced into a design. The "specification" class and the "implementation" classes must share an interface. That is, the implementation classes must, at a minimum, support the full interface that the "specification" class publishes to the rest of the system. Since the implementation classes are added over time, and often by other than the original developer, it is easy to miss some subtle clause of the pre-condition. This leads to an inconsistency among the subclasses. Careful checks, including boundary tests, are essential to determining that the implementation classes support the specification.
Summary
I have tried to stimulate your thinking about the relationship between specifications and testing. Each component has a specification that describes the intended behavior. It’s either in the mind of the developer and the rest of us must try to guess what it is or it may be written in a format that supports both development and testing. The quality of that specification, how complete, correct and consistent it is, determines the quality of the tests that can be constructed and ultimately the quality of its implementation.
Next month I will discuss several notations used for representing specifications and some techniques for constructing tests from those specifications.
References